Sen Fang
 |
|
I'm Sen Fang, a first-year Ph.D. student at Rutgers University, supervised by Prof. Dimitris Metaxas.
My main research field is Multimodal. My research interest covers Audio-Visual (talking-face and representation of text/audio, Audio Generated Image), AIGC (AI-generated content, Multi-view learning, NeRF/3D), Self-Supervised Learning (Pose recognition and modeling, object & action detection/recognition in videos, Medical Image Analysis) and VR/AR/DCG and Visual Perception (Enables the agent to make plan and navigate)!
Recently I have been interested in the following topic:
- LLM/HCI/Embodied Intelligence - I will bring agents that can interact with scenes or people to reality, whatever it takes.
- Identify and Model Behavior - particularly in perceiving and synthesizing dynamic humans, objects, and scenes. I think controlling robots by self-supervised training through real-world data and Computer Vision related technologies is the right path.
- Sign Language - It involves many fields, such as the conversion between text/audio and movement/gestures, human body reconstruction and recognition, human pose synchronization, Pose-guided image generation, avatar reconstruction, and style transfer, etc. This topic has high technical requirements, and you must achieve a high level in all the above fields before it can be applied to sign language datasets.
I am open to academic collaborations, and please drop me an email if you are interested in collaborating with me.
Recent News
- 2024.6 I got the Best Bachelor's Thesis award of Henan University.
- 2024.2 I have received the offer of dream advisor and will start my doctoral career.
Representative Works
* Equivalent contribution, † Corresponding author
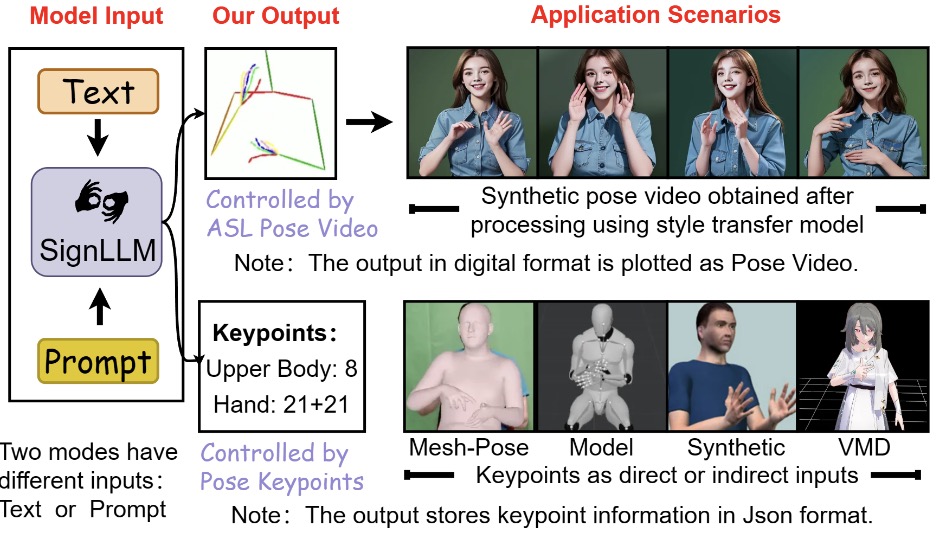 |
SignLLM: Sign Language Production Large Language Models
|
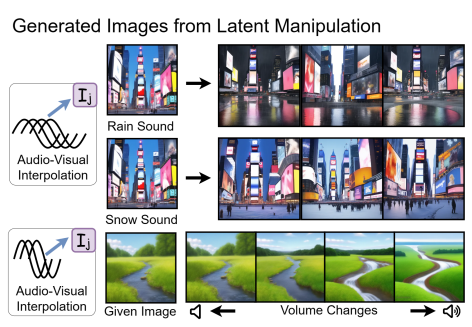 |
Bridging the Gap between Text, Audio, Image, and Any Sequence: A Novel Approach using Gloss-based Annotation
|
 |
SignDiff: Diffusion Models for American Sign Language Production
|
→ List of Selected Publication
Part of Friends (random sort)
Extend
Georgia Institute of Technology: Hongbin Zhong
Columbia University: Chunyu Sui
Toronto University: Haris Khan
Tsinghua University: Jiayin Zhu
University of Waterloo: Yifan Wang
Nanyang Technological University: Yalin Feng
University of Washington: Yangyang Wu